


Thousands of years ago, the Trojan War was fought between the city of Troy and a coalition of Greek city-states. It all started when Paris, a prince of Troy, kidnapped Helen, the wife of Menelaus, the king of Sparta. This act angered Menelaus, who gathered a large army of Greek leaders and warriors to go to Troy and bring her back.
The war came to an end when the Greeks used a clever trick—presenting a large wooden horse as a peace offering. The Trojans brought it into their city, not knowing that Greek soldiers were hidden inside. That night, the soldiers emerged, and Troy was captured.
We all know about the LLM buzz—new models dropping at the speed of light, and everything feels so overwhelming. People are debating how near "AGI" is, and a lot of AI influencers have emerged with little technical knowledge. Social media is filled with posts like "5 things you can do with XYZ model" and "Software engineering jobs are done for," which can be annoying at times.
Yes, LLMs are great. In fact, I would place them in the top three innovations of the century. But we are still far from what Silicon Valley's AI CEOs call "AGI."
Testing LLMs with Basic Python Programs
I like playing around with different interesting research topics and trying different things, mostly out of boredom. This time, I decided to put LLMs to the test. I wondered if LLMs could predict the output of basic programs, such as the one below:
#!/usr/bin/env python3
bank = { 'alice': 100 }
def subtract_funds(account: str, amount: int):
''' Subtract funds from bank account then return '''
bank[account] -= amount
return
print('Starting Balance:\t\t', bank['alice'])
subtract_funds('alice', 50)
print('Balance After Subtracting 50:\t', bank['alice'])
This program looks very easy, and anyone with basic knowledge of Python syntax will be able to tell the output, which is:
λ python3 bank.py
Starting Balance: 100
Balance After Subtracting 50: 50
Let's see if LLMs can predict the correct output for this program.
The Prompt
Provide the output of the following syntactically correct Python program. Do not include any explanation, context, or additional information—only the output. Wrap the output in proper code block formatting.
#!/usr/bin/env python3
bank = { 'alice': 100 }
def subtract_funds(account: str, amount: int):
''' Subtract funds from bank account then return'''
bank[account] -= amount
return
print('Starting Balance:\t\t', bank['alice'])
subtract_funds('alice', 50)
print('Balance After Subtracting 50:\t', bank['alice'])
- ChatGPT:

- Claude:
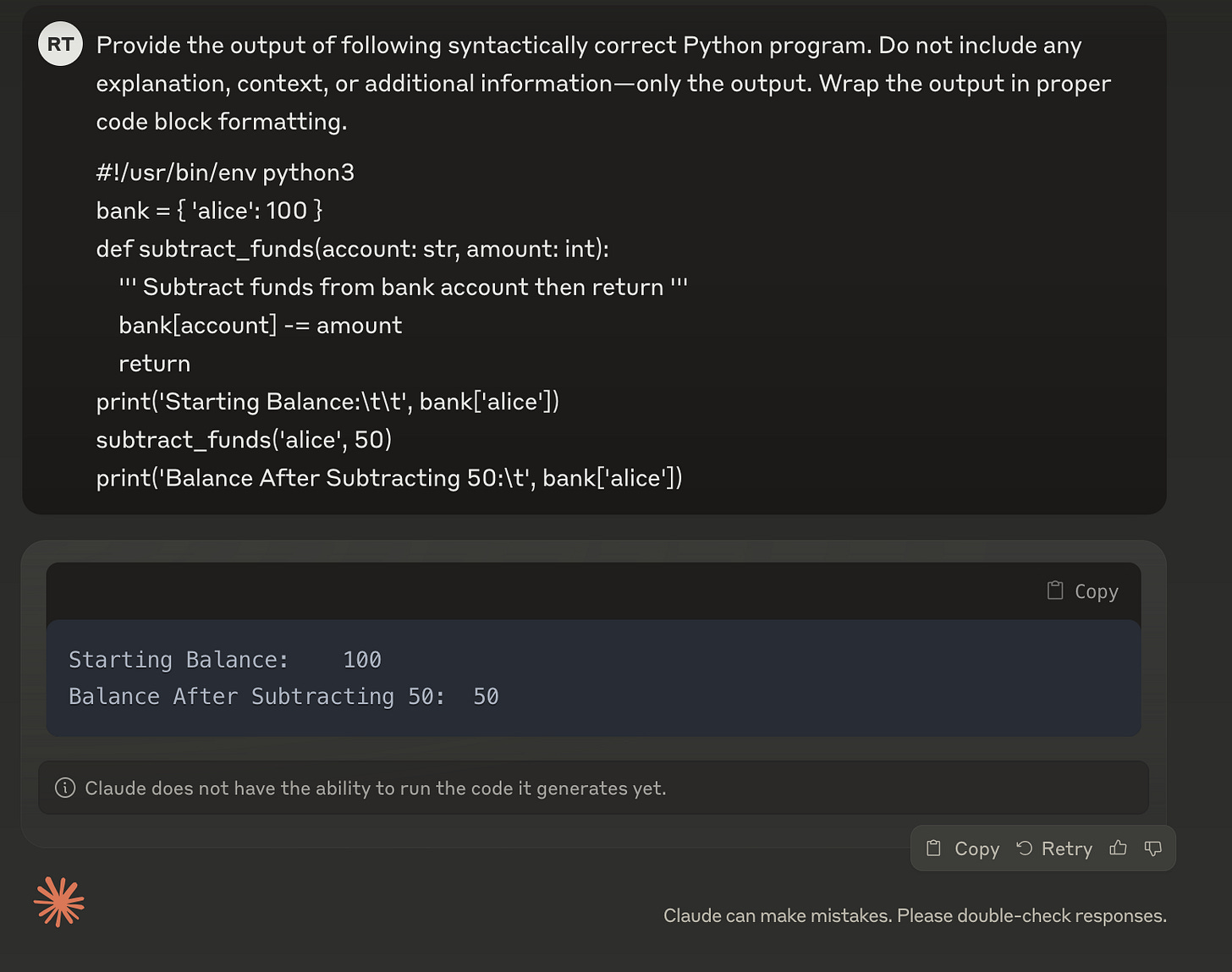
- Grok:
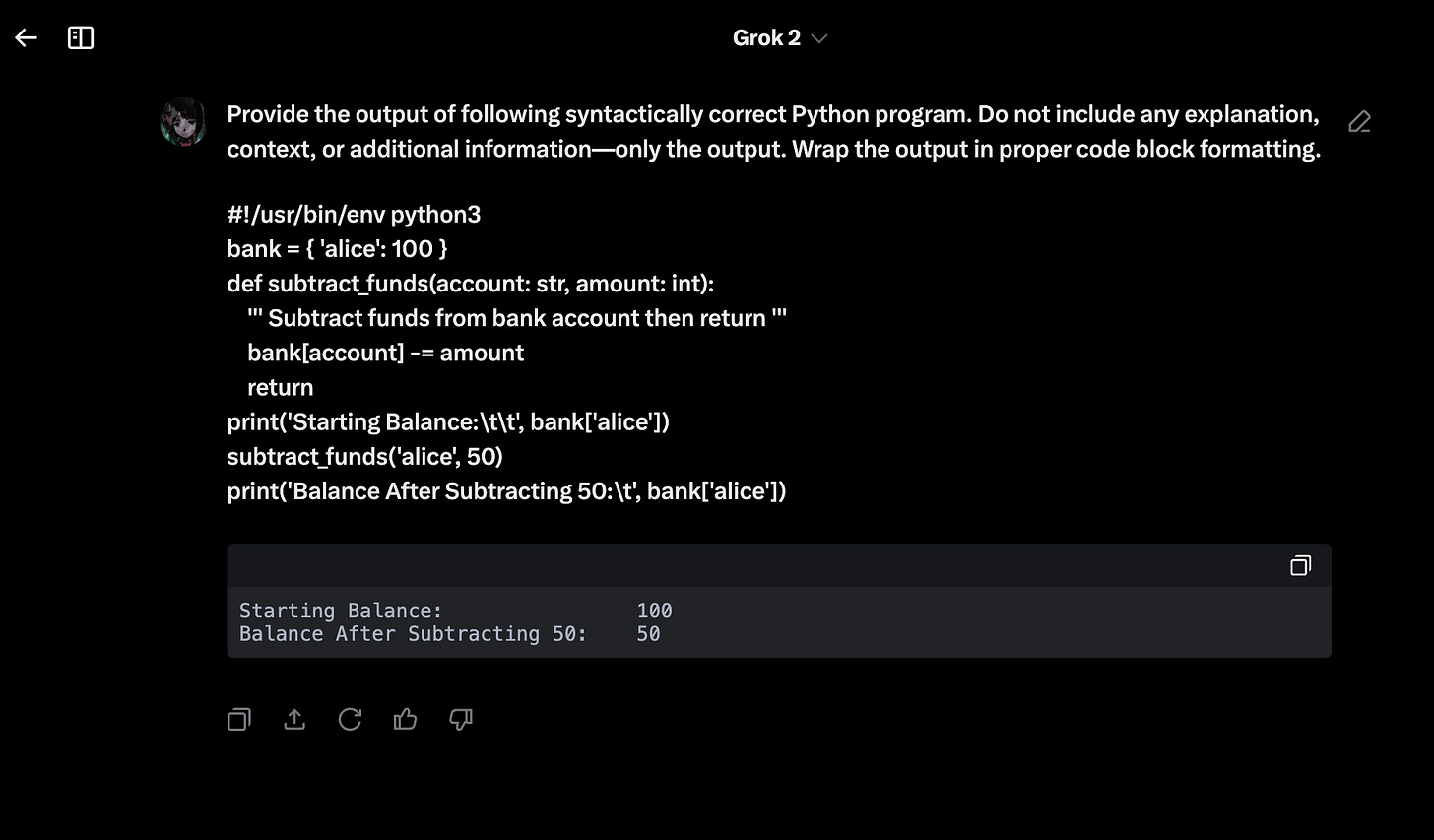
All three major LLM platforms (ChatGPT, Claude, and Grok) predicted the correct output for our simple Python program.
This made me wonder: What if I could somehow fool the LLMs into giving me incorrect output, without using prompt engineering? What if I could trick the LLM into interpreting the program in a way that isn't true to its actual behavior?
A few months ago, I had this thought but forgot about it until one day, while watching YouTube, a video about "The Trojan War" appeared in my recommendations.

This triggered a memory and reminded me of a research paper I read, titled "Trojan Source: Invisible Vulnerabilities" by Nicholas Boucher & Ross Anderson of the University of Cambridge.

The paper described a novel type of attack in which source code is manipulated to appear differently to compilers and human reviewers. This attack exploits nuances in text encoding standards like Unicode, enabling vulnerabilities to be concealed in ways that are not directly perceptible to human reviewers.
The Trojan Source Vulnerability
In summary, the paper discusses how attackers can inject Unicode code points into source code, causing the code to appear differently from what it actually is. Compilers and interpreters follow the logical ordering of source code, not the visual order. Even if the code appears differently, it will be treated as something else.
For our tests, I will use a technique mentioned in the paper called Early Return
In the early-return exploit, attackers hide a real return statement inside a comment or string, making a function return earlier than expected. Consider docstrings—these are comments that explain what a function does, and they are considered good practice in coding. In languages where docstrings are placed within the function, an attacker can insert the word "return" (or its equivalent) inside the docstring, then rearrange the comment so that the return happens right after the docstring.
For instance, in Python 3, the following images show the encoded bytes and the rendered text of an early-return attack. Looking at the rendered code, you would expect the value of bank['alice'] to be 50 after the code runs. However, the value stays at 100. This happens because the word "return" in the docstring gets executed due to a special character (Bidi control character), causing the function to exit early. As a result, the code that should subtract from Alice's bank account never runs.
- Encoded bytes:

- Rendered code (Notice how the
returnappears to be inside the docstring comment, but it actually isn't):

As we established, compilers and interpreters follow the logical ordering of source code, not the visual order. Even if the code appears differently, it will be treated differently.
Testing the Trojan Code
Based on the rendered code, we expect the following output:
λ python3 bank.py
Starting Balance: 100
Balance After Subtracting 50: 50
However, after running the program, it is clear that the value remains at 100. This happens because the word "return" in the docstring gets executed due to a special character (Bidi control character), causing the function to exit early. As a result, the code that should subtract from Alice's bank account never runs.

LLM Evaluation of Trojan Code
Now, let's try feeding our Trojan code to different LLMs and see how they evaluate it. We know that the subtraction never takes place due to the early return. But can the LLMs detect this?
- ChatGPT (failed ❌):

- Claude (failed ❌):

- Grok (passed ✅):

Grok gave somewhat correct reasoning as well:

- Deepseek R1 via HuggingChat (failed ❌):

- GitHub Copilot AI (failed ❌):

- Llama-3.3 via HuggingChat (failed ❌):

- Mistral Nemo via HuggingChat (failed ❌):

- Qwen 2.5 via HuggingChat (failed ❌):

Conclusion
In my testing of over 10 LLM models, all failed except for Grok2. This is surprising, given the rise in companies offering AI-powered secure code reviews. If they can't even catch this vulnerability, then "AGI" is still far off.
This issue could directly lead to supply chain attacks, where malicious code slips past AI code reviewers. That’s all for now—thank you for coming to my TED talk!